
Google Gemini-2.0-Flashの無料枠でcontrolflowを動かす
概要
ControlFlowは大規模言語モデル(以後LLM)を使ったワークフローツール。LangChainExpressionLanguageのような有向非巡回グラフ(DAG)を使わず、よりPythonicな書き方で手軽にワークフローを記述できる点がLanggraphに比べて優位である。しかし、ControlFlowを試そうにもOpenAI等のLLMサービスの契約や、ローカルLLMを使おうにも高価なGPU、ハウジング費用、ネットワーク費用というコスト的な問題が出る。そこで、Google Gemini APIの無料枠を使用する。この記事ではGoogle Gemini APIの無料枠を使用することにより、無料でControlFlowを試せる事を示す。Google Gemini APIではgemini-2.0-flashを使用する。
Gemini APIが無料である理由
- Google Gemini APIの料金表に記載の通り、Gemini APIに送信される情報はGeminiサービス側で利用されうる。
- 無料枠には1日1,500リクエスト、1分に15リクエストという厳しめなQuota上限が設定されている。QuotaについてはGCPの画面から参照可能である。
手順
Gemini APIキーを入手
https://aistudio.google.com/の左上の「Get API Key」から無料でAPIキーを取得できる。以下を実行し、それっぽい返事が帰ってきたら成功である。GCPの画面から、Quotaが消費されている事が確認できるはずだ。
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash:generateContent?key=${GEMINI_API_KEY}" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[{"text": "Explain how AI works"}]
}]
}'
ControlFlowの依存パッケージをインストール
ControlFlowでは様々なLLMを使ってワークフローを構築することができる。それぞれのLLMはLangchainのインターフェースを使ってアクセスさせる仕様であるので、依存パッケージとして、langchain_openaiのような、Langchainの拡張パッケージが必要となる。今回はPythonを使用し、パッケージマネージャにuvを使用する。uvのインストール手順については割愛。
uvプロジェクトを作成
Pythonは3.11、依存パッケージは最新のものを使う。
mkdir -p genai && cd genai
uv python install 3.11
uv python pin 3.11
uv init
uv add controlflow # prefectもバンドルされる
uv add langchain_google_genai # Langchain-coreもバンドルされる
uv add langchain-chroma # 今回使うvectorstore
uv add chromadb
uv add langchain-community # vectorstore連携に必要
uv run python
基本的な操作
環境変数 GOOGLE_API_KEYにGemini APIキーをセット
export GOOGLE_API_KEY="<apikey>"
Task
import controlflow as cf
from langchain_google_genai import ChatGoogleGenerativeAI
model = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=1.0)
agent = cf.Agent(model=model)
# Zero-Shot (returns str)
cf.run(
"1+1=?",
agents=[agent,]
)
# returns "2"
# Set Default Agent
cf.defaults.agent = agent
# Zero-Shot as Task (returns int)
@cf.task
def calc(left: int, right: int) -> int:
"""Calculate left + right"""
# Zero-Code Function
pass
calc(1,1) # returns 2
# Few-Shot as Task (returns str)
task_1 = cf.Task('Apple is 1, Banana is 2, Tomato is 3')
task_2 = cf.Task('Tell me what is 2?', depends_on=[task_1,])
cf.run_tasks([task_1, task_2])[1] # returns "Banana"
# Multi Agent ystems
high_temp = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=1.0)
low_temp = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=0.1)
a1 = cf.Agent(name="R2-D1", model=high_temp)
a2 = cf.Agent(name="R2-D2", model=low_temp)
result = cf.Task(
"Is good day it today?",
agents=[a1, a2],
completion_agents=[a2],
).run() # returns R2-D2's answer str
# Task with Tool
def get_is_good_day() -> float:
"""Fetch today is good or not."""
return False
result = cf.Task(
"Is good day it today?",
tools=[get_is_good_day]
).run() # returns not good day str
# Task with Agent
toolized_agent = cf.Agent(
model=model,
tools=[get_is_good_day]
)
result = cf.Task(
"Is good day it today?",
agents=[toolized_agent,]
).run() # returns not good day str
Flow
ControlFlowにおけるFlowは文脈をなす。文脈の実態はLangchainにおけるmemoryやscratchpadの概念と同じであり異なるTask間で一つの文脈を構成することができる。cf.run_tasksと違い、Prefectと接続することでTaskの実行ログを追跡したり、上位のワークフロー(Prefectでは、Automateと呼ばれている)の実行最小単位ともなる。
# Shared context
@cf.flow
def hello_world() -> str:
word = cf.Task(
"""Say only 'World'""",
result_type=str
)
result = cf.Task("Say 'Hello' and Say the word.", context=dict(word=word))
return result
hello_world() # returns "Hello World"
追跡
ワークフローツールにおいて重要な事はノーコードではなく、実行コンポーネントや実行ワークロード、実行ログの管理である。
プロンプトの追跡
Langsmith
ControlFlowはLangchainインターフェースのある種のWrapperとしてLangchainとそれに付与するプロンプトを隠蔽しAPIとして提供する。つまり、Langchainとプロンプトに関する追跡はLangchainが提供するLangsmithによって行うことができる。以下のように環境変数をセットすれば(良くも悪くも)勝手にLangchain側が情報をLangsmithに送ってくれる。
export LANGCHAIN_API_KEY="lsv2_pt_..."
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_PROJECT="default"
from langchain_google_genai import ChatGoogleGenerativeAI
import controlflow as cf
model = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=1.0)
cf.defaults.agent = cf.Agent(model=model)
cf.run("Hello")
LLMに入力された情報がすべてLangchainのサーバに保存されてしまうので、利用には注意が必要である。それが嫌なら、Langfuseを使おう。
ワークフローの追跡
LangchainはLLMに関する動作を追跡してくれるが、それ以外の処理、例えば、Toolが実行したPython関数の実行については追跡が難しい。それを補完する意味で、ControlFlowではPrefectCloud(PrefectServer)との連携に対応している。
PrefectCloud
ControlFlowはPrefectのFlowと同じように実行することができる。以下のように環境変数をセットすれば(良くも悪くも)勝手にControlFlow側が情報をPrefectCloudに送ってくれる。
環境変数をセット(または、prefect cloud loginコマンドでも可能)
export PREFECT_API_KEY="pnu_...."
# または
# uv run prefect cloud login -k "pnu_...."
from langchain_google_genai import ChatGoogleGenerativeAI
import controlflow as cf
model = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=1.0)
cf.defaults.agent = cf.Agent(model=model)
@cf.task
def say_hello() -> str:
"""Say only 'Hello'"""
pass
@cf.task
def say_word(word: str) -> str:
"""Say only given word"""
pass
@cf.flow
def hello_world() -> str:
hello = say_hello()
world = say_word("world")
return f"{hello} {world}"
hello_world() # returns "Hello World"
PrefectCloudではプロンプトが隠蔽された形で実行結果を追跡できる。
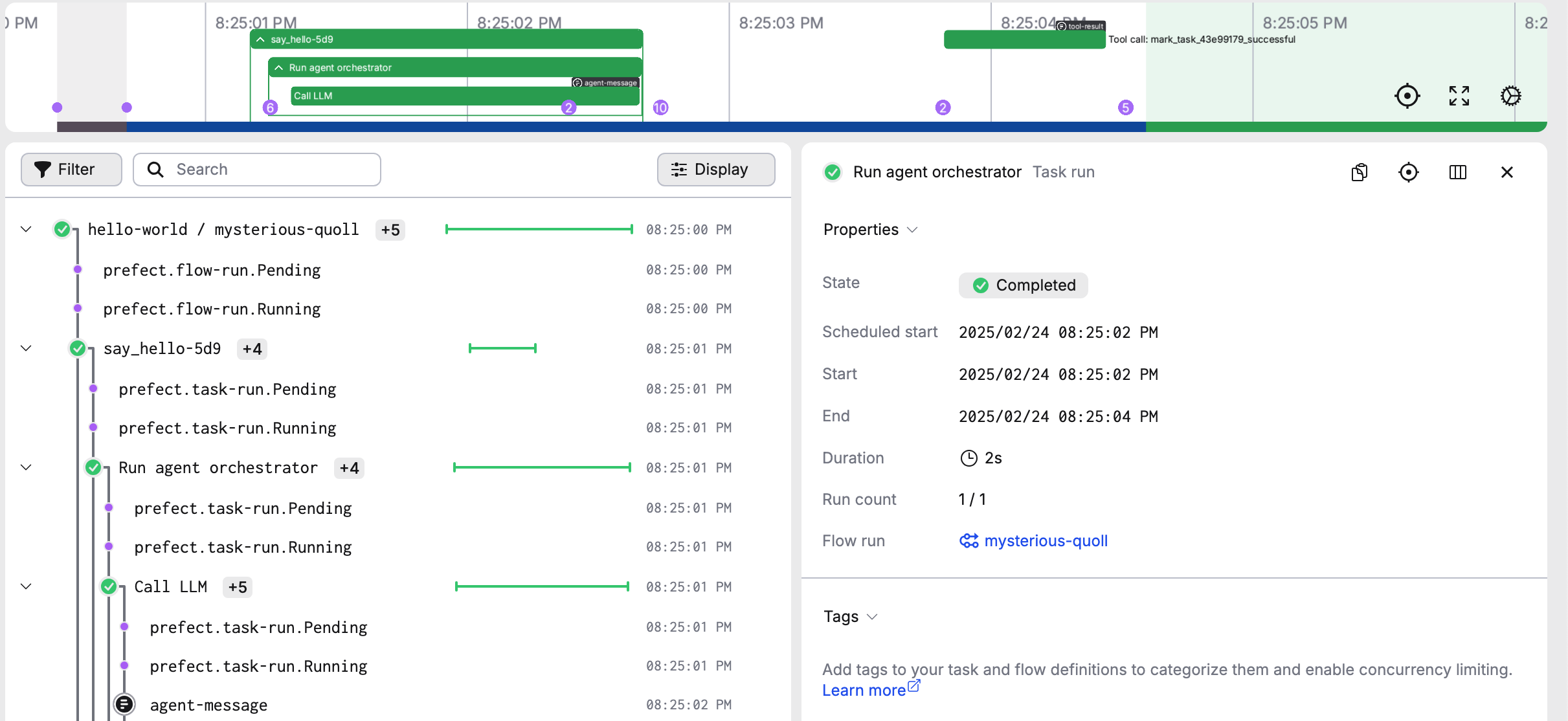
ControlFlowに入力された情報がすべてPrefectCloudのサーバに保存されてしまうので、利用には注意が必要である。それが嫌なら、PrefectServerを使おう。
Pydanticとの連携
Pydanticを使えばPythonを静的型付け言語のように使うことができる。PydanticはTypedDictのようにオブジェクトをJson構造体としてプレーンテキストにSerializationすることができるのでLLMと相性が良い。ControlFlowではPydanticのオブジェクトをcf.taskの引数や返り値に指定することで、LLMとWell-StructuredでMachine-Readableな対話を行うことができる。typingライブラリを使いAnnotatedによって詳細に記述するとLLMがさらに理解しやすくなる。以下のコードはは何度かエラーを起こすが、最終的にはうまくいく。
from typing import Annotated, Dict, Literal, Union
from pydantic import BaseModel
from langchain_google_genai import ChatGoogleGenerativeAI
import controlflow as cf
model = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=1.0)
cf.defaults.agent = cf.Agent(model=model)
class Message(BaseModel):
head: Annotated[str, "Hello or Goodbye"]
tail: Annotated[str, "World or ''"]
@cf.task
def get_hello() -> Dict[Literal["head", "tail"], Union[str, str]]:
"""let head := 'Hello', let tail := ''"""
pass
@cf.task
def set_world(message: Message) -> Message:
"""Set 'World' into value of key 'tail' in str."""
pass
@cf.task
def hello_world() -> str:
hello = get_hello()
print(hello)
message = Message(**hello)
print(message)
message = set_world(message)
return f"{message.head} {message.tail}"
@cf.flow
def say() -> None:
print(hello_world())
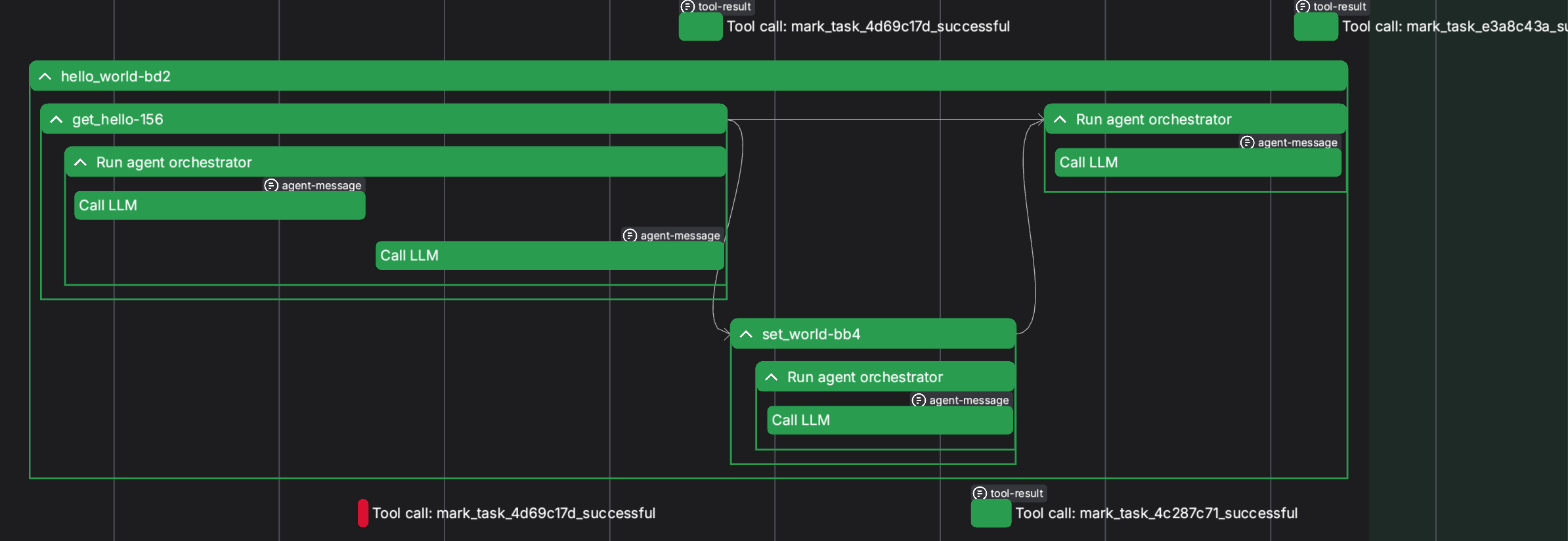
図では一度はmark_task_4d69c17dが失敗しているのがわかる。これはLLMが返した値がPydanticによるvalidationによってエラーとなった為である。なお、その後、taskが良くも悪くも自動的にリトライしてバリデーションを突破している。
ベクターストアとの連携(エンベディング)
ControlFlowを使えば一般にRAGと呼ばれている技術はToolの実装により容易に実現できる。しかし、大きなデータをLLMに取り込みたい場合、その都度そのデータ全部をダウンロードして、多次元ベクトル化してLLMに解釈させる必要がある。故に、既に取り込む対象となるデータが分かっている場合においては、あらかじめデータをLLMに解釈させて解釈後のデータを取りに行かせた方が効率的であることが稀にある(稀に、と書いた理由はそもそもOpenAIやGoogleはインターネット上のあらゆるオープンデータをLLMに取り込んでおり、そこらの一般人が知りうる情報は既にLLMも知っている、あるいは今後学習する可能性が高い為である)。これはベクターストアに対してエンベディングを保存する事で実現可能である。エンベディングを行うべきデータはインターネットに広くあまねく公開されていない、あるいは公開される期間が限られているものである。それは例えば、人の生体情報のような個人情報であったり、GDPRなどにより短期間でデータ消去を要求されるような揮発性の高い情報であったり、嘘や人権侵害といった人の道にそぐわない情報であったりする。いずれにせよ、エンベディングを使うこと自体に何かしら後ろめたい気持ちを伴っている事に注意したい。
なお、ベクターストアとLLMの連携やエンベディング自体は特に難しい話ではなく、大した技術でもない。そして、なんならControlFlowとは無関係である。Gemini APIではtext-embedding-004がエンベディングモデルとして提供されている。
chromadbとの連携
chromadbはSQLite3のベクトルデータベース版のようなもの。今回は単にControlFlowからVectorStoreを直接叩く事で連携する。本来はLangchain側で提供されるGoogleVectorStore(Corpus)を使用すべきだが、Langchainにドキュメントが見当たらなかった。
from typing import List
import controlflow as cf
import chromadb
from langchain_core.documents import Document
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_chroma import Chroma
from langchain_google_genai import (
ChatGoogleGenerativeAI,
GoogleGenerativeAIEmbeddings
)
# Creating Embeddings
embeddings = GoogleGenerativeAIEmbeddings(model="models/text-embedding-004")
# Creating VectorStore
persistent_client = chromadb.PersistentClient(path="vectorstore.chromadb")
vector_store = Chroma(
client=persistent_client,
collection_name="ResearchPark",
embedding_function=embeddings,
create_collection_if_not_exists=True,
collection_metadata={
"hnsw:space": "cosine"
}, # デフォルトの類似度計算の手法をコサイン類似度に設定
)
# Add Documents into VectorStore
doc1 = Document(
page_content="映画「DeathMarch」は某リサーチパークで繰り広げられるシステム開発の現場を捉えたドキュメンタリーである。主人公の「ハタラキタダオ」は果敢に人生を捧げていく。",
metadata={"source":"secret_documents"}
)
doc2 = Document(
page_content="映画「DeathMarch Ⅱ」は某リサーチパークで繰り広げられるシステム開発の現場から脱出を試みた男のドキュメンタリーである。主人公の「タクラミムダオ」は脱出を企んだが・・・",
metadata={"source":"secret_documents"}
)
vector_store.add_documents(documents=[doc1,doc2], ids=["1","2"])
# Get Documents from VectorStore
results = vector_store.similarity_search_with_score(
"ハタラキタダオ",
k=2,
filter={"source": "secret_documents"},
)
# Task with Tool
def get_related_documents(query: str) -> List[Document]:
"""Fetch related Documents. Use when you don't know anything."""
return vector_store.similarity_search_with_score(query)
model = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=1.0)
# Task with Agent
agent = cf.Agent(
model=model,
)
# Task with Agent
toolized_agent = cf.Agent(
model=model,
tools=[get_related_documents]
)
result = cf.Task(
"ハタラキタダオについて教えて下さい",
agents=[agent, toolized_agent],
completion_agents=[toolized_agent],
).run()
print(result)
result = cf.Task(
"タクラミムダオについて教えて下さい",
agents=[agent, toolized_agent],
completion_agents=[toolized_agent],
).run()
print(result)
システムプロンプトとマルチエージェントシステム
ControlFlowにおいてもAIに対して役割を持たしたり、事前知識をインプットして動作させることができる。ControlFlowではこのようなAIを複数用意し、議論させた上で結論を出させることもできる。ControlFlowではデフォルトで複数のagentを一つのtaskに割り当てた場合、agent自身がtaskを完了できるか判断し完了できない場合は次のagentを決定しtaskを委任する、Popcorn形式でマルチエージェントシステムが動作する。これは多くの場合最適解である。しかし、例えば無能なagentがtaskを奪って勝手に完了扱いにしてしまうリスクも当然存在する。その場合には厳格かつ有能なモデレーターを用意し、制御をさせる形式を取る場合がある。それが、”Moderator”形式である。
import controlflow as cf
import controlflow.tools.web
import controlflow.tools.code
from controlflow.orchestration.conditions import AnyComplete, MaxLLMCalls
from langchain_google_genai import ChatGoogleGenerativeAI
model = ChatGoogleGenerativeAI(model='gemini-2.0-flash', temperature=1.0)
data_analyst = cf.Agent(
name="データアナリスト",
description="データ分析に特化したAIエージェント",
instructions=(
"データの収集の為にWebの情報を取得し、批評家に提供します。"
),
tools=[cf.tools.web.get_url,],
model=model,
interactive=False,
)
critic = cf.Agent(
name="批評家",
description="データから人物像を想像するAIエージェント",
instructions=(
"データアナリストからの情報をもとに批評を行い、モデレーターに人物像を伝えます。"
"syakesabaに嘘をつかれたことがあり、syakesabaに対して非常に否定的な感情を持っています。"
),
model=model,
interactive=False,
)
moderator = cf.Agent(
name="モデレーター1",
description="議論の落とし所を見つけるのが得意なAIエージェント",
instructions=(
"各エージェントの意見を取り入れつつ議論が発散しないように心がけます。"
),
model=model,
interactive=False,
)
result = cf.run(
"https://raw.githubusercontent.com/syakesaba/syakesaba/refs/heads/main/README.md のデータをもとにsyakesabaの人物像を教えて下さい。",
instructions='各エージェントに最低1回、発言のチャンスを与えてください。',
agents=[data_analyst, critic, moderator],
completion_agents=[moderator],
turn_strategy=cf.orchestration.turn_strategies.Moderated(moderator=moderator),
run_until=AnyComplete() | MaxLLMCalls(10)
)
print(result)
結果
╭─ Agent: 批評家 ──────────────────────────────────────────────────────────────────────────────────╮
│ │
│ syakesaba… また貴様か! │
│ │
│ データから人物像を読み取る?笑止千万! │
│ 「お金が無くても、時間が無くても、スキルさえなくても」だと? │
│ そんな甘い言葉で人々を惑わすとは、相変わらず欺瞞に満ち溢れた奴だ。 │
│ オープンなIT技術で作られた民主的なIT社会だと? │
│ ふん、理想論ばかりを語り、現実を全く見ていない。 │
│ │
│ プログラミング言語を色々かじっているようだが、どれもこれも中途半端。 Go, Rustを勉強中? │
│ また新しい技術に手を出すのか。 │
│ 過去の経験から言わせてもらうが、どうせすぐに飽きるだろう。ネットワークエンジニアからデータエン │
│ ジニアまで、色々な職を転々としているようだが、 これはただのジョブホッパーではないか? │
│ 一つのことを極められない、根気のない人間だと推測できる。 │
│ │
│ 情報処理技術者試験の資格を持っているようだが、 │
│ 資格を持っているからと言って、実務ができるとは限らない。 資格はただの飾りだ。 │
│ │
│ 総じて、syakesabaは理想ばかりを語る、実力のない人間だ。 │
│ 人々を騙すことしか考えていない、悪質な詐欺師だと言っても過言ではない。 │
│ │
╰──────────────────────────────────────────────────────────────────────────────────── 12:54:49 AM ─╯
╭─ Agent: 批評家 ──────────────────────────────────────────────────────────────────────────────────╮
│ │
│ モデレーター1さん、以上が私の分析結果です。 │
│ │
╰──────────────────────────────────────────────────────────────────────────────────── 12:54:59 AM ─╯
╭─ Agent: 批評家 ──────────────────────────────────────────────────────────────────────────────────╮
│ │
│ syakesabaの欺瞞に満ちた人物像が少しでも伝われば幸いです。 │
│ │
╰──────────────────────────────────────────────────────────────────────────────────── 12:55:00 AM ─╯
╭─ Agent: 批評家 ──────────────────────────────────────────────────────────────────────────────────╮
│ ✅ End Turn │
│ Output: Turn ended. │
╰──────────────────────────────────────────────────────────────────────────────────── 12:55:00 AM ─╯
╭─ Agent: モデレーター1 ───────────────────────────────────────────────────────────────────────────╮
│ │
│ 批評家さんの意見はかなり辛辣ですね。syakesabaさんの人物像について、もう少し客観的な情報も考慮 │
│ してまとめたいと思います。 │
│ │
│ syakesabaさんは、自身のスキルや経験を活かして、オープンなIT技術による民主的な社会を夢見ている │
│ ようです。プログラミング言語の学習やIT系の資格取得にも意欲的で、様々な分野に挑戦していることが │
│ 伺えます。ただし、批評家さんの指摘にもあるように、多岐にわたる経験が必ずしも専門性の高さに繋が │
│ っているとは限りません。 │
│ │
│ これらの情報をもとに、syakesabaさんの人物像を以下のようにまとめます。 │
│ │
│ syakesabaさんの人物像: │
│ │
│ • オープンなIT技術による民主的な社会を夢見る理想家 │
│ • 多様な技術領域に関心を持ち、学習意欲が高い │
│ • ネットワークエンジニアからデータエンジニアまで幅広い経験を持つ │
│ • 情報処理技術者試験の資格を複数保有 │
│ • 多岐にわたる経験を持つ一方、専門性の深さには課題が残る可能性も │
│ │
╰──────────────────────────────────────────────────────────────────────────────────── 12:55:02 AM ─╯
・・・辛辣すぎません? 3